按照之前做题目的惯例,在开始之前先摆个链接:
比赛链接: https://ac.nowcoder.com/acm/contest/5759#description
官方题解: https://ac.nowcoder.com/discuss/428597?type=101&order=0&pos=4&page=1&channel=-1&source_id=1_101
至于官方题解,因为不算是公开比赛,所以还没有找到;如果找到了会挂在这里的。已经找到了
啊这啊这,半个月不做算法题目了,真就什么都不会了呗== 再过几天校队还要再次排位刷人,啊这……
Z94XW8MDFSI4NBN_H9H.jpg 希望人没事== 得赶紧地把空窗期补回来了。
这次比赛一共有五个题目,但是比赛时长五个小时;从同步赛的榜单来看,除了第一的 AK 爷之外,其他的过题数量都小于 3;这至少证明了这场比赛具有一定的难度不适合萌新从空窗期恢复的性质。
补完了题感觉就没有那么难了…… 啊这,还是自己太鸡儿菜了;每个思路基本都是有道理的,只不过是真的不会写代码== 吐了吐了,希望能好起来吧(
定义“好序列”指的是这个序列存在至少一个元素与这个序列的其他任何元素都不同;
给定一个长度小于 2e5 的序列,要求判断它的所有子串是否都是“好序列”。
*原题说是唯一一个元素,但是仔细思考应该还是至少一个元素。
这题整第一个直接把我给读傻了,而且作为第一题有着极高的尝试数== 所以没做出来我人就傻了(
但是也不能说是毫无思路:一个数字一旦不能使它所在的序列的好序列,那一定是因为它在这个序列中还有一个一样的数字;所以显然需要预处理一个数字左右两端最近的相同数字的位置;接下来考虑这个左右位置的区间 [L, R]:假设这个数字的位置是 M,那么可以确定的是 [L, M] - [M, R] 一定都是好序列。
这样就可以进行分治:找到了唯一的 M,就可以确保一个端点来自 M 两侧的区间是“好序列”;接下来只需要考虑两个端点都在一侧的区间的情况:此时问题已经被 M 划分成了子问题,可以重复上述方法,直到子串长度为 1;
两种情况可以特判:若全序列不存在一个唯一的 M,又或者序列中存在连续的区间,那么这个序列一定不是符合要求的序列。这可以在扫描过程中直接判断出来。
此外,如果从两头出发向中间寻找,最坏情况就是在序列中间找到唯一值,可以证明复杂度是 O(nlogn)。
这样我们就可以写出 DFS 的分治搜索的代码了。
我的代码 根据上面的分析:首先特判,如果发现两个连续的数字直接俯冲;随后标记位置,使用 map 是 O(nlogn) 的,将每一个在区间内无重复的点作为分治点,将区间分为两个区间继续处理,直到区间大小缩为 2;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 #include <iostream> #include <map> using namespace std ;using longs = long long ;using longd = long double ;using ulongs = unsigned long long ;const int N = 2e5 + 5 ;int n, a[N], pre[N], nex[N];bool cannot = false ;bool dcDFS (int ll, int rr) if (ll >= rr) return true ; auto ii = ll; while (ii <= rr) { if (pre[ii] < ll && nex[ii] > rr) return dcDFS(ll, ii - 1 ) && dcDFS(ii + 1 , rr); ++ ii; } return false ; } int main () ios::sync_with_stdio(false ); cin .tie(nullptr ); cin >> n; map <int , int > mp; a[0 ] = 0 ; const int tail = n + 1 ; for (int i = 1 ; i <= n; ++ i) { cin >> a[i]; if (a[i] == a[i - 1 ]) cannot = true ; if (mp[a[i]]) { pre[i] = mp[a[i]]; nex[mp[a[i]]] = i; } else pre[i] = 0 ; mp[a[i]] = i; nex[i] = tail; } if (cannot) cout << "fuchong" << endl ; else { cannot = !dcDFS(1 , n); cout << (cannot ? "fuchong" : "chong" ) << endl ; } return 0 ; }
虽然数字可以很大,但是总数有限,所以还是可以使用 map 日常当作稀疏数组使用
有一个长度为 n 的数列 a,以及一个无限长的递推数列 F;对于 F > 2,它满足 \(F_n = 3F_{n-1} + 2F_{n-2}\) ,此外,有\(F_1 = 1,\ F_3 = 3\) ;对于数列 a,要求实现下列区间操作:
对于有效区间 [l, r],对于任意 l ≤ i ≤ r,\(a_i\) 加上 \(F_{i-l+1}\) ; 对于有效区间 [l, r],对于任意 l ≤ i ≤ r,对 \(a_i\) 求和并且取模; 要求对于给定的请求序列,输出所有上述第二种请求的结果。
首先,看到是区间操作,大脑第一反应是想到线段树;线段树如果加上了懒惰标记,做乘法或者修改其值,想必也是可以的吧;但是问题是这个题目加上的不是一般值,是一个数列;所以使得这个题目变得麻烦了起来,也就是所谓的“代码量多”;但是虽然这样,本质上还是一个带懒惰标记的线段树上的区间修改。
啊这,但是为什么这题公开赛下 A 的数量最少啊……虽然我也写代码写了好久,那没事了(
首先从递推公式下手:既然是递推公式,肯定有办法写成矩阵方式;首先从给定值的两种情况入手,可以推导出 F₀ = 0;然后经过简单的推导,可以得到下面的两种矩阵表达形式:
\[ \begin {bmatrix} F_{n+1} & 2F_n \\\\ F_n & 2F_{n-1} \\\\ \end {bmatrix} = \begin {bmatrix} F_n & 2F_{n-1} \\\\ F_{n-1} & 2F_{n-2} \\\\ \end{bmatrix} \cdot \begin {bmatrix} 3 & 2\\\\ 1 & 0 \end {bmatrix} \]
代码里采用的是这一种形式,当然也可以采用下面这种:
\[ \begin {bmatrix} F_{n+1} & F_n \\\\ 0 & 0 \\\\ \end {bmatrix} = \begin {bmatrix} F_n & F_{n-1} \\\\ 0 & 0 \\\\ \end{bmatrix} \cdot \begin {bmatrix} 3 & 1\\\\ 2 & 0 \end {bmatrix} \]
啊这,这矩阵又不能正常显示,我吐了我吐了== 又得找时间修(这转义就有些离谱==
最后的代码采用的是上述第一种表达式,原因请看下面的分析——第二种也可以用只是会麻烦许多(
啊等等,别介,这样一来,这个题目是不是不用矩阵乘法也可以?矩阵乘法的意义何在?
1BWR9RSVN472XJIE03LP.jpg ↑ 椿姐的凝视 ↑ 啊这,这…… 这不太行——笔者写代码的时候为数不多的已提交代码都是使用了矩阵乘法,所以一定是哪里出现了一些误会;先放着不管我们继续说(
然后首先预处理一下数列在范围内的值和前缀和,就可以开始构筑线段树部分了;懒惰标记在这里的使用方式是这样子的:首先,线段树建立两个,一个就是标准意义上的线段树,统计了每个区间节点的和,并且叶子节点是具体的数组成员;另外建立一个空的 lazy 树,用来存放一些标记。
当读取到指令需要加上一个数列的时候(假设需要加上数列的区间是 [l, r]),可以确定的是这个区间的总和会增加 \(\sum_{i=1}^{r-l+1} F_i\) ,每一个真正的节点加上的值可以通过和 l 的相对定位求出来;为了省事,我们直接这样操作:加上值的时候,在懒惰树上操作,当节点区间被待处理区间完整覆盖的时候,就直接在这个区间上加上这段数列的和(因为已经预处理过,所以可以快速得出),并且在懒惰节点中记录这个节点的首值;
众所周知,一般的懒惰标记的线段树的区间修改是所有区间加上同一个值——总之是进行同一个操作,然后当需要使用子节点的时候,再将这个操作应用到子节点上;但是因为本次加上的是一个数列,所以这样的操作大概是不可行的(当然,你的懒惰节点也可以是一个数组,记录每一次修改的首值下标,这样也是可以的);但是现在就体现使用矩阵的优势了:首先,上述矩阵表达式 1 的开始的情况是矩阵 I₂(有的书上将单位矩阵记作 E);所有的矩阵都是通过乘一个相同的变换矩阵得到的,记变换矩阵为 B,则整个矩阵序列可以看成是 {~, I₂, B, B², B³, ...},这样即使懒惰标记节点只是记录了这个区间多次修改的矩阵和,使用一个可以容易的计算出的位置偏移(下标做差)得到 B^n,由于矩阵乘法的性质,相乘就可以得到位移过的矩阵的和;
那么如何修改子节点的值呢?因为矩阵乘法性质,懒惰节点记录的本质是偏移;再加上子区间的大小非常的好求,求出子区间的大小之后乘以偏移就可以得到目标区间的修改值;
我的代码 使用上述矩阵表达式一,写出的代码是下面这样:可能有一些问题,因为理论上更加亲民的 GNU g++ 14 在线跑出了和本地 CLion C++ 14 不一样的结果,但是一般来说不太行的 clang++ 11 却AC了;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 #include <iostream> #include <cstring> #include <algorithm> using namespace std ;using longs = long long ;using longd = long double ;using ulongs = unsigned long long ;const int inf = 0x3f3f3f3f ;const longs INF = 0x3f3f3f3f3f3f3f3f ;const double eps = 1e-8 ;const longs mod = 998244353 ;const int N = 1e5 + 5 ;template <int n> struct matrix { longs m[n][n]; matrix() = default ; longs &operator () (unsigned i, unsigned j) { return m[i][j]; } matrix operator +(const matrix<n> &rhs) const { matrix<n> res; for (int i = 0 ; i < n; ++ i) for (int j = 0 ; j < n; ++ j) res.m[i][j] = (m[i][j] + rhs.m[i][j]) % mod; return res; } matrix &operator +=(const matrix<n> &rhs) { for (int i = 0 ; i < n; ++ i) for (int j = 0 ; j < n; ++ j) m[i][j] = (m[i][j] + rhs.m[i][j]) % mod; return *this ; } matrix operator -(const matrix<n> &rhs) const { matrix<n> res; for (int i = 0 ; i < n; ++ i) for (int j = 0 ; j < n; ++ j) res.m[i][j] = (m[i][j] - rhs.m[i][j] + mod) % mod; return res; } matrix operator -=(const matrix<n> &rhs) { for (int i = 0 ; i < n; ++ i) for (int j = 0 ; j < n; ++ j) m[i][j] = (m[i][j] - rhs.m[i][j] + mod) % mod; return *this ; } matrix operator *(const matrix<n> &rhs) const { matrix<n> res; for (int i = 0 ; i < n; ++ i) for (int j = 0 ; j < n; ++ j) res.m[i][j] = 0 ; for (int i = 0 ; i < n; ++ i) for (int j = 0 ; j < n; ++ j) for (int k = 0 ; k < n; ++ k) res.m[i][j] = (res.m[i][j] + m[i][k] * rhs.m[k][j] % mod) % mod; return res; } }; using mat = matrix<2 >;longs a[N]; mat sum[N], p[N]; void preProcess () p[1 ](0 , 0 ) = p[1 ](1 , 1 ) = 1 ; p[1 ](0 , 1 ) = p[1 ](1 , 0 ) = 0 ; sum[1 ] = p[1 ]; mat xx; xx(0 , 0 ) = 3 , xx(0 , 1 ) = 2 , xx(1 , 0 ) = 1 , xx(1 , 1 ) = 0 ; for (int i = 2 ; i <= N; ++ i) { p[i] = p[i - 1 ] * xx; sum[i] = sum[i - 1 ] + p[i]; } } namespace segTree{ mat tree[N << 2 ], lazy[N << 2 ]; void upMerge (unsigned root) { tree[root] = tree[root << 1u ] + tree[root << 1u ^ 1u ]; } void downSplit (unsigned root, unsigned l, unsigned r) { auto mid = (l + r) >> 1u ; lazy[root << 1u ] += lazy[root]; lazy[root << 1u ^ 1u ] += lazy[root] * p[mid + 2 - l]; tree[root << 1u ] += sum[mid - l + 1 ] * lazy[root]; tree[root << 1u ^ 1u ] += (sum[r - l + 1 ] - sum[mid - l + 1 ]) * lazy[root]; memset (lazy[root].m, 0 , sizeof (lazy[root].m)); } void build (unsigned root, unsigned l, unsigned r) { memset (lazy[root].m, 0 , sizeof (lazy[root].m)); tree[root] = lazy[root]; if (l == r) tree[root](0 , 0 ) = a[l]; else { auto mid = (l + r) >> 1u ; build(root << 1u , l, mid); build(root << 1u ^ 1u , mid + 1 , r); upMerge(root); } } void update (unsigned root, unsigned l, unsigned r, unsigned ll, unsigned rr) { if (ll <= l && r <= rr) { lazy[root] += p[l - ll + 1 ]; tree[root] += sum[r - ll + 1 ] - sum[l - ll]; } else { downSplit(root, l, r); auto mid = (l + r) >> 1u ; if (mid >= ll) update(root << 1u , l, mid, ll, rr); if (mid < rr) update(root << 1u ^ 1u , mid + 1 , r, ll, rr); upMerge(root); } } longs query (unsigned root, unsigned l, unsigned r, unsigned ll, unsigned rr) { if (ll <= l && r <= rr) return tree[root](0 , 0 ); downSplit(root, l, r); auto mid = (l + r) >> 1u ; longs ans = 0 ; if (mid >= ll) ans = (ans + query(root << 1u , l, mid, ll, rr)) % mod; if (mid < rr) ans = (ans + query(root << 1u ^ 1u , mid + 1 , r, ll, rr)) % mod; return (ans % mod + mod) % mod; } } int main () ios::sync_with_stdio(false ); cin .tie(nullptr ); preProcess(); int n, m; cin >> n >> m; for (int i = 1 ; i <= n; ++ i) cin >> a[i]; segTree::build(1 , 1 , n); while (m --) { int op, ll, rr; cin >> op >> ll >> rr; if (ll > rr) swap(ll, rr); if (op == 1 ) segTree::update(1 , 1 , n, ll, rr); else cout << segTree::query(1 , 1 , n, ll, rr) << endl ; } return 0 ; }
啊这,线代白给不可取== 果然数学题还是数学一点的好啊;我们来欣赏一下标准答案的说法:
由特征方程 \(\alpha^2 = 3\alpha + 2\) 解出特征根 $= {2} $; 使用待定系数法得到通项公式:$ F_n = {} (( {2})^n + ( {2})^n) $; 暴力测试得到 17 的二次剩余 473844410,处理两个模意义下的特征根; 所以可以用两颗线段树维护区间加等比数列、区间求和的操作;懒标记记录首项,应用到区间的时候直接更新为等比数列求和;标记的合并可以直接相加,但是要预处理两个特征根的 1~n 次方。
所以说矩阵还是不是必须的== 啊这就这(
本轮的签到题;下面是题面:
问一个数 n 能不能和 k 个正偶数和 k 个正奇数的和相等;
最小的正奇数是 1;最小的正偶数是 2;也就是说 k 个正奇数和 k 个正偶数的和一定大于 3k;此外,对任何一个整数加上一个偶数不会改变这个数的奇偶性,所以 n - 3k 必然应当是一个偶数,且大于等于 0;
我的代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 #include <iostream> using namespace std ;using longs = long long ;using longd = long double ;using ulongs = unsigned long long ;int main () ios::sync_with_stdio(false ); cin .tie(nullptr ); int t, n, k; cin >> t; while (t --) { cin >> n >> k; n -= k; cout << ((n >= 2 * k && n % 2 == 0 ) ? "Yes" : "No" ) << endl ; } return 0 ; }
虽然实现的和上面分析中所说的不太一致,但是基本就是这么一回事。
这竟然是一个板子题==
首先,有一个大小为 n 的整数数组,记每一个元素为 A[i];你可以对这个数组进行下面的区间操作:
将 [l, r] 区间里的数字每一个都加上 k; 将 [l, r] 区间里的数字每一个都乘以 k; 将 [l, r] 区间里的数字修改为 k; 在数组的最后增加一个数字,值为 k; 除了进行这些操作,还需要在任何时候在线查询一个区间内所有数字的和;此外所有运算在模 p 意义下。
如果使用线段树,那就需要动态开点线段树了;这我不太会 == 但是这个题还可以用另一种简单粗暴的数据结构来解决,也就是这个题目的板子:珂朵莉树(老司机树,ODT);
这显然是一个自创的数据结构,但是有点非常的显著:仅仅使用 STL 和简单的代码实现就可以达到一个不错的平均复杂度;但是缺点是这些修改必须是随机的,如果不是随机的话这个数据结构将会退化的很惨;不过参考其他博客的带佬们的说法,似乎一般出题人并不会卡掉这种做法,但是还是有可能所以需要注意;
ODT,使用 STL set 实现,可以达到复杂度 O(nlog²n),对于区间修改是一种取巧的数据结构;它使用 set 将每一个节点(区间节点)以及它们的值存储起来:当需要修改一些值的时候,就将已经有的区间拆开,修改后重新插入 set 中;如果需要修改一个区间的值的时候,也只需要将这些区间的节点取出,合并成一个区间并置相同的值,再作为新节点插入到 set 中;查找节点全程使用 lower_bound / upper_bound,所以实现起来基本就和上面的描述那样顺畅所以我超喜欢珂朵莉。
当然,听了上面的描述,你应该也很容易发现这珂朵莉树其实根本算不上是一棵树:它其实只有一层父子关系,找到对应区间的子节点使用的方法是二分查找;所以想要在这个节点后面加一个新节点也是非常轻松,只需要在 set 的尾部加入新节点就可以了。
至于初始化 ODT,只需要把所有的数字作为一个单个区间插入 set 就可以了,复杂度 O(nlogn);啊这完全就是乱搞嘛 == 这要是没有大量的区间设置操作合并区间的话,简直就是直接暴毙的节奏啊(
我的代码 使用 split 函数拆分节点区间,使用 assign 合并区间节点;仅有区间设置 k 的操作使用了 assign;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 #include <iostream> #include <set> using namespace std ;using longs = long long ;using longd = long double ;using ulongs = unsigned long long ;int n, m, p;namespace ODT{ template <class T > struct node { int l, r; mutable T val; node(int l, int r, const T &v) : l(l), r(r), val(v) {} node(int l, int r, const T &&v) : l(l), r(r), val(v) {} bool operator <(const node<T> &rhs) const {return l < rhs.l;} }; using number = longs; using iter = set <node<number>>::iterator; using func = void (*) (iter &, void *); set <node<number>> odt; iter split (int x) { auto it = odt.lower_bound(node<number>(x, 0 , 0 )); if (it != odt.end () && it -> l == x) return it; const number v = (-- it) -> val; const int l = it -> l, r = it -> r; odt.erase(it); odt.insert(node<number>(l, x - 1 , v)); return odt.insert(node<number>(x, r, v)).first; } void assign (int l, int r, number v) { auto rr = split(r + 1 ); auto ll = split(l); odt.erase(ll, rr); odt.insert(node<number>(l, r, v)); } void run (int l, int r, func todo, void *param) { auto rr = split(r + 1 ); auto ll = split(l); for (; ll != rr; ++ ll) todo(ll, param); } func add = [](iter &it, void *para) { const number value = *(number*)para; it->val = (it->val + value) % p; }; func mul = [](iter &it, void *para) { const number value = *(number*)para; it->val = (it->val * value) % p; }; longs _sum = 0 ; func sum = [](iter &it, void *para) { _sum = (_sum + it->val * (it->r - it->l + 1 )) % p; }; } int main () ios::sync_with_stdio(false ); cin .tie(nullptr ); cin >> n >> m >> p; longs x, tail = n + 1 ; for (int i = 1 ; i <= n; ++ i) { cin >> x; ODT::odt.insert(ODT::node<longs>(i, i, x)); } auto last = ODT::node<longs>(tail, -1 , -1 ); ODT::odt.insert(last); while (m --) { int op, l, r; longs k; cin >> op; switch (op) { case 1 : cin >> l >> r >> k; ODT::run (l, r, ODT::add, &k); break ; case 2 : cin >> l >> r >> k; ODT::run (l, r, ODT::mul, &k); break ; case 3 : cin >> l >> r >> k; ODT::assign(l, r, k); break ; case 4 : { cin >> k; auto it = ODT::odt.lower_bound(last); ODT::odt.erase(it); ODT::odt.insert(ODT::node<longs>(tail, tail, k)); last = ODT::node<longs>(++ tail, -1 , -1 ); ODT::odt.insert(last); break ; } case 5 : cin >> l >> r; ODT::_sum = 0 ; ODT::run (l, r, ODT::sum, &k); cout << ODT::_sum << endl ; break ; default : break ; } } return 0 ; }
特别注意:当switch语句中需要新建变量或者特别长的时候,要使用花括号包覆;
一个计算几何的题目。
给定了一个二维坐标系,已知原点和 x 坐标轴上的一个确定点;此外,还给了第一象限中的 n 个点;
现要求你从 n 个点中选出一些点,这些点中的每一个点和 原点 - 确定点 构成三角形,要求形成的三角形是严格的互相嵌套——每个三角形和其他三角形除了 原点 - 确定点 共有之外没有其他任何的公共边或者交点;问最多可以在给定的点集中选出多少点。
保证给出的第一象限的点不重复(
在这之前:这个题目和之前做过的“汉诺塔拼盘”,“看星星”(只记得大概的题目名字了)很像——包含关系的成立取决于两个维度,需要同时满足才可以包含,寻找包含关系的最大值。
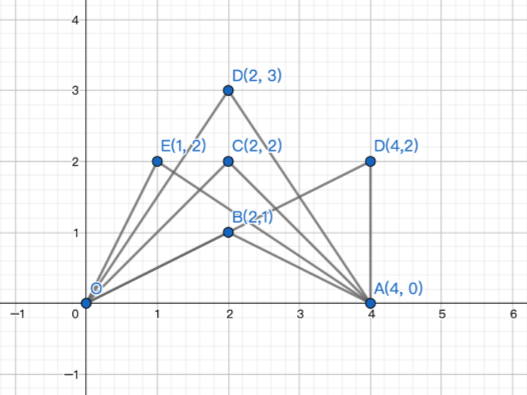
这种题目满嘴跑火车还是不可取,所以要有图;把题面里给的样例的一张图搬过来:
999991351_1589784561169_30097379256A480B09E6D5A8DF2B6B26.png 因为是共有边 OA,所以如果 △OCA 包含了 △OBA,那么一定有 ∠BOA < ∠COA 和 ∠BAO < ∠CAO 同时成立;如果用斜率来表示,那就是 |k(OC)| > |k(OB)| 和 |k(AC)| > |k(AB)| 同时成立。这两个三角形就在图中可以轻松的看出来,对于一般的两个这样的三角形也一定是这样吧。
一种最简单的方法就是:因为斜率具有上述的关系,所以可以对于所有在第一象限内的点 X,分别按照 k(OX) 和 k(AX) 进行排序,并对排序得到的两个序列寻找最长公共子序列——显然,这个子序列的长度就是答案;当然,实现的时候也可以只排序一次,并再增长这个序列的时候判定另一个斜率是否符合标准。
当然,你也可以像标准答案 那样,使用权值线段树来维护以满足要求;具体做法如下:
所有点按照到原点的极角排序,将另一个角的值排序后离散化 建立维护最大值的权值线段树,每一个节点维护一个区间内的节点的最大答案 更新答案时:查找区间节点中的最大值并且单点修改 需要注意极角相同时的情况;因为感觉太过麻烦这一回就不写这种做法的代码了,请参考官方题解。
我的代码 根据斜率寻找最长公共子序列:按照 OX 斜率排序后的向量,如果 AX 的斜率更加有优势就更新;直到所有的向量都扫描完之后,整个序列的大小就是答案。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 #include <iostream> #include <cmath> #include <algorithm> using namespace std ;using longs = long long ;using longd = long double ;using ulongs = unsigned long long ;namespace Geo{ using number = int ; struct point { number x, y; point () = default ; point (number x, number y) : x(x), y(y) {} point operator +(const point &rhs) const { return {x + rhs.x, y + rhs.y}; } point operator -(const point &rhs) const { return {x - rhs.x, y - rhs.y}; } number operator *(const point &rhs) const { return x * rhs.x + y * rhs.y; } point operator *(const number rhs) const { return {rhs * x, rhs * y}; } point operator /(const number rhs) const { return {x / rhs, y / rhs}; } point &operator +=(const point &rhs) { x += rhs.x; y += rhs.y; return *this ; } point &operator -=(const point &rhs) { x -= rhs.x; y -= rhs.y; return *this ; } point &operator *=(const number rhs) { x *= rhs; y *= rhs; return *this ; } point &operator /=(const number rhs) { x /= rhs; y /= rhs; return *this ; } bool operator ==(const point &rhs) const { return x == rhs.x && y == rhs.y; } bool operator !=(const point &rhs) const { return !(rhs == *this ); } number dot (const point &rhs) const { return x * rhs.x + y * rhs.y; } number cross (const point &rhs) const { return rhs.y * x - rhs.x * y; } number length () const { return sqrt (dot(*this )); } number distance (const point &b) const { return (*this - b).length(); } number distance (const point &ls, const point &rs) const { return fabs ((ls - *this ).cross(rs - *this )) / ls.distance(rs); } point normal () const return (x || y) ? *this / length() : point (0 , 0 ); } number angle () const { return atan2 (y, x); } point rotate (number a) const { number c = cos (a), s = sin (a); return {c * x - s * y, s * x + c * y}; } point perpendicular () const return {-y, x}; } point symmetry () const return {-x, -y}; } bool operator <(const point &rhs) const { auto ll = 1l l * y * rhs.x; auto rr = 1l l * x * rhs.y; return ll < rr; } bool operator >(const point &rhs) const { auto ll = 1l l * y * rhs.x; auto rr = 1l l * x * rhs.y; return ll > rr; } }; } const int N = 1e5 + 5 ;int n, m, upto, dp[N];Geo::point p[N], v[N]; int binary (const Geo::point &now) int ll = 1 , rr = upto, res = 0 ; auto ii = Geo::point (m - now.x, -now.y); while (ll <= rr) { int mid = ll + rr >> 1 ; if (v[mid] < ii) res = mid, ll = mid + 1 ; else rr = mid - 1 ; } return res; } int main () ios::sync_with_stdio(false ); cin .tie(nullptr ); while (cin >> n >> m) { auto pp = Geo::point (m, 0 ); for (int i = 1 ; i <= n; ++ i) cin >> p[i].x >> p[i].y; sort(p + 1 , p + 1 + n, greater<Geo::point >()); upto = 0 ; for (int i = 1 ; i <= n; ++ i) { dp[i] = binary(p[i]) + 1 ; v[dp[i]] = pp - p[i]; upto = max (upto, dp[i]); } cout << upto << endl ; } return 0 ; }
binary 函数用来找到斜率可以更新的位置;但是最终 dp 数组内的向量未必可以指示实际选出的点,这点还请多加注意。
后记 虽然做的时候很痛苦,但是补题的时候却没有什么没学过的知识点…… 这不太行== 我已经不会做题力(
还有一大堆没有做的题目等着我去补,呜呼!