




软件工程:第 3 次上机实验

下面是这一次的实验要求:
#####软件工程综合实验 一、实验名称:软件工程综合实验
二、实验目的
掌握软件分析、设计、测试和实现基本方法
综合运用测试驱动开发和重构
三、实验内容和要求
开发一个机器可读的英汉词典,能获得给定英文词条的多方面信息(读音、词性、每个词义、例句等,能提供的信息越多越好),并在其他软件系统(桌面或在线词典、机器翻译系统、其他自然语言处理系统等)中使用
根据常见纸质英汉词典(如牛津高阶英汉词典等)的内容和结构,给出详细的机器可读英汉词典的功能需求
设计机器可读英汉词典的存储结构(词典需要存储在磁盘中和内存中)
设计机器可读英汉词典的接口
采用熟悉的语言(OOP优先)进行实现
采用测试驱动的开发方法进行开发
采用重构完善设计和实现
四、实验时间
2次上机时间
实验过程
设计一个使用 TDD 方法的机器可读的词典。
需求分析
从实验要求入手,对于实验要求的部分进行合理解释;
词典
通过传入的字符串,在内建的数据库中搜索对应或者相关的词条;也可以对于某个特定的单词在数据库中查找它全部的相关信息(包括释义、例句以及词性);
机器可读
按照约定的规则向其他应用程序返回格式化的数据;比如作为一个库提供 API 给其他的程序调用,或者作为一个服务端,向对它发起请求的客户端返回合适的数据;在本次实验中,我将词典核心部分打包成 C++ 共享库,可以方便的在其他的 C++ 程序/工程中使用;
存储
SQLite3 是一个轻量级的数据库,它支持全部的 SQL 特性,且数据库作为一个文件存储在本地的文件系统中;对于一个离线的字典工具,使用 SQLite3 作为数据库显然是非常的合适的。
测试驱动
因为涉及到数据库的操作需要验证准确性,且 C++ 没有现成的较好的 ORM 框架,所以在构筑上层程序之前,首先需要先编写和 SQLite3 API 通信的框架;每当完成一部分的时候,都应该对这个框架的方法进行测试;
实现
实现的平台是: Windows 10 + CLion + MinGW + CMake,使用了 SQLite3 作为底层数据库;
简介
项目分为三个部分:控制台Shell,C++ 共享库,共享库测试demo;您可以点击这些链接来访问它们的仓库;是基于 CMake 的项目,可以跨平台编译并且运行;项目提供了 API 打开 SQLite3 词典数据库(这里,以 Kelinsi 电子词典的数据库设计作为标准),然后提供封装后的 API 来查询单词,或者获得某个确定单词的相关信息;
机器可读和测试
用户可以在自己的 C++ 工程中引入本项目生成的库文件,在本文档或头文件的引导下使用 API 打开词典数据库,并且查阅单词,对于返回的数据,项目也提供了必要的 Demo 和 API 来获得用户想要查询的信息;Shell 项目和 Demo 项目已经测试了全部的 API,保证它们可以在测试数据集中正常运行;
关于测试框架:使用 Boost.Test 对比接口查询的数据和 SQL Shell 查询的数据,但是 Git 的时候弄丢了,所以无了。现在仅剩下 Demo 项目和 Shell 项目下的 Test 文件夹下的测试用代码;
此外,编译生成的库中的 hello 函数,也是用来测试项目是否正确的连接到你的工程的,请多加注意;
数据库设计
这是 Kelinsi 电子词典数据库的表结构:

一个单词可能有多个释义,不同的释义可能有很多条的信息(比如例句),它们通过保存彼此的主键作为自己的外键来关联到一起,是典型的关系型数据库;
API 设计
本项目基于 SQLite3 本地数据库,基于该数据库系统的特点设计 API;以下仅列出关键的 API 的声明,如果您需要完整的 API,可以阅读项目工程中提供的 eDict_library.h 文件中的声明;
1 |
正常的工作流程是,在开始查询之前运行 OPEN_DICTIONARY(path) ,并且通过 DICTIONARY_IS_CONNECT 确认字典数据库是否已经连接;若连接,再使用查询相关的 API 查询单词;当程序结束时,建议手动调用 CLOSE_DICTIONARY() 断开连接。
如果您还想使用这些代码进行更高级的操作,您可能需要了解关于这个项目的结构设计:
orm.h:可以和 SQLite3 数据库通信,执行 SQL 语句,并且将返回的结果作为一个OBJECT对象返回;这个对象的本质上是 STL 实现的哈希表,且当前的版本不能很好地实现BLOB格式的数据的读取;edict.h:是 ORM 的子类;将执行 SQL 的接口进行进一步的封装,暴露传入回调函数的接口;此外将上文 API 中规定的查询行为特化,返回基于 Kelinsi 电子词典设计的数据结构;
工作开始时,可以实例化一个 edict 对象,你可以发现这个对象持有上述简易 API 宏所涉及的所有相关的函数;此外,你可以通过暴露的 execSQL 方法执行任何复杂的查询,并通过设计类型为 CALLBACK 的回调函数,将返回的 Meta 数据处理成为任何你想要的数据结构。切记,在工作结束后使用 close 方法结束对于数据库文件的占用。
1 | class database { |
eDict_library.h 中) ↑重构
虽然在 Shell 工程中将代码分成多个文件存放是好的,但是当要制作一个库的时候,将太多高度耦合的文件分开存放并不是一件好事,会增大用户使用的复杂度;所以打包成成品库之后,我将很多高度耦合的头文件的代码进行了融合,作为一个新的工程与原来的 Executable 工程分开;
此外,在我的代码中,一些常用的功能已经被提取成纯函数,作为单独的模块而存在;
使用
关于库文件的 API,已经在上面讲过了;想要知道更多请去阅读相关头文件;
Excutable 项目
从代码仓库中获得代码后,使用 CMake 加载这个项目,编译可以得到可执行文件;将可执行文件和电子词典数据库文件放在相同的目录下,关闭杀毒软件即可查询;
Library 项目
从代码仓库获取代码之后,使用 CMake 生成 .dll 文件;将这个文件以及项目目录下的 sqlite3.h 和 edict_library.h 文件放在你要使用的项目里,并且加入 Include Path(也可以忽略此步,但是这样大多数 IDE 将不能为这里的代码提供自动补全或者只智能纠错);在编译时使用 -l libedict_library.dll 命令,或者(你使用 CMake 管理你的项目)在你自己的项目的 CMakeList.txt 中加入以下内容:
1 | include_directories(./) # 用来存放 dll 的位置 |
如果你使用 Visual Studio 管理你的项目,你需要在解决方案的配置页面,在 C/C++ > 链接器 的页面中加入这个 dll 文件。
这样,你就可以使用上述的 API 来查询符合 Kelinsi 词典表规范的电子词典数据库了;实际上,Demo 项目已经实现了这个功能,但是在使用之前,您仍然需要将电子词典数据库文件放在生成的可执行文件相同的目录下,并且修改文件名;
Win32 + CMake
你可以下载已经编译过的DLL文件和头文件来在 CMake 项目中使用这个程序;当然,这里也提供 kelins 电子词典的 SQLite3 数据库文件,可以配合上述文件以及介绍快速地在您的项目中使用。
后记
通过本次的软件工程实验,我学会了使用 SQLite3 数据库框架,熟练了 CMake 对于项目管理的流程;实际操作了在现代 IDE 中的项目管理流程,一定程度上熟悉了 TDD 开发以及 C++ 测试框架,并且对于库文件开发的理解更进一步。
关于源代码
展示的源代码是 Library 项目的源代码,它的文件结构如下图所示:
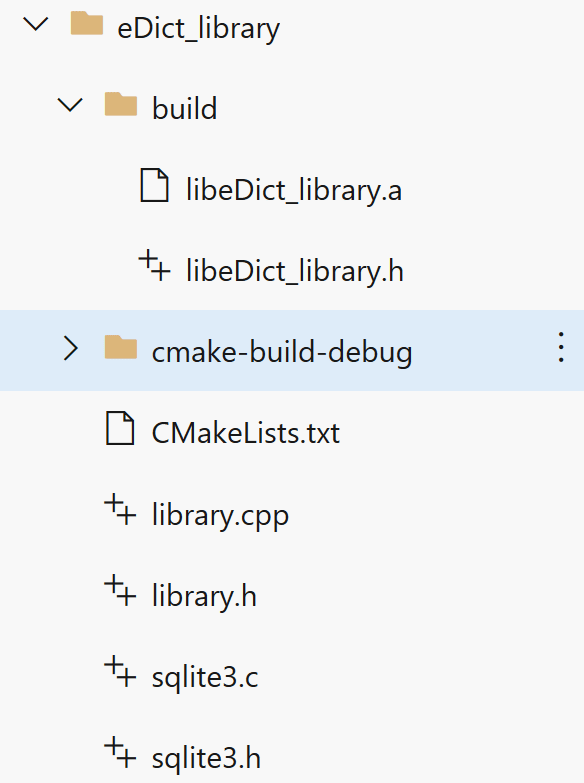
其中 cmake-build-debug 是 CMake 生成的临时文件,可以忽略;但是作为生成的可执行文件的所在位置,如果你要运行其他两个 C++ Executable 项目的话,需要将数据库文件放在该目录下;
build 目录是手动生成的输出位置,如果生成静态库就会得到 .a 文件,生成共享库文件就会得到 .dll 文件;其中的 libedict_library.h 文件就是前面可以直接下载的头文件,它包含了 SQLite3 的头文件;
CMakeList.txt 文件记录了项目的配置信息;如果不是直接从仓库拉取项目,这个文件的内容可能需要重新配置;
sqlite3.c 和 sqlite3.h 文件是 SQLite3 官方 API 的一部分,您可以从它的官方网站上下载,并且将它们包含在这个项目的目录中;注意,如果您下载的文件版本和仓库中的版本不一致,可能会导致运行结果和预想不一致甚至是无法编译的问题,请根据实际情况进行酌情调整;
library.h 和 library.c 包含了对于底层 SQLite3 API 的封装以及面向用户的宏的声明和实现;编译后可以将这里的头文件和上面的 SQLite3 的头文件一起加入到新项目中以使用代码智能提醒;