树上分治主要是针对于树上路径问题的,一种使用分治思想解决的方法。主要分为树分治(树上点分治、边分治)以及动态树分治两个部分。
点分治 适合处理大规模的树上路径信息问题。
例题 ##### luogu P3806【模板】点分治 1 给定一颗 n 个点的带点权树,m 次询问,每次询问给出 k,询问树上距离为 k 的点对是否存在。
n ≤ 1e5,m ≤ 100,k ≤ 1e9
先随意选择一个节点作为根节点 rt:这样,所有完全位于其子树中的路径可以分为两种—— 一种是经过当前根节点的路径,一种是不经过当前根节点的路径;对于经过当前根节点的路径,又可以分为两种,一种是以根节点为一个端点的路径,另一种是两个端点都不为根节点的路径;而后者又可以由两条属于前者链合并得到。
因此,对于枚举的根节点 rt :我们可以先计算在其子树中且经过该节点的路径对答案的贡献,再递归其子树对不经过该节点的路径进行求解。
对于这个题目,对于经过根节点 rt 的路径,我们先枚举其所有子节点 ch ,以 ch 为根计算 ch 子树中所有节点到 rt 的距离。记节点 i 到当前根节点 rt 的距离为 \(d_i\) , \(tf_d\) 表示之前处理过的子树中是否存在一个节点 v 使得 \(d_i\) = d 。若一个询问的 k 满足 \(tf_{k-d_i}\) = true ,则存在一条长度为 k 的路径。在计算完 ch 子树中所连的边能否成为答案后,我们将这些新的距离加入 tf 数组中。
一般来说,清空 tf 数组不应使用 memset,这会导致 TLE;正确的做法是将之前使用过的位置加入一个数组中,清空的时候使用这个数里的记录值清空,才可以保证时间复杂度。
点分治过程中,每一层的所有递归过程合计对每个点处理一次,假设共递归 h 层,则总时间复杂度为 O(nh)。但是若我们每次选择子树的重心作为根节点,可以保证递归层数最少,时间复杂度为 O(nlogn)。每一次在确定根节点之前统计子树大小,并且找到一个根,使得最大子树大小最小,就找到了重心。
请注意在重新选择根节点之后一定要重新计算子树的大小,否则一点看似微小的改动就可能会使时间复杂度错误或正确性难以保证。
例题的代码(来自 OI Wiki):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 #include <algorithm> #include <cstdio> #include <cstring> #include <queue> using namespace std ;const int maxn = 20010 ;const int inf = 2e9 ;int n, m, a, b, c, q[maxn], rt, siz[maxn], maxx[maxn], dist[maxn];int cur, h[maxn], nxt[maxn], p[maxn], w[maxn];bool tf[10000010 ], ret[maxn], vis[maxn];void add_edge (int x, int y, int z) cur++; nxt[cur] = h[x]; h[x] = cur; p[cur] = y; w[cur] = z; } int sum;void calcsiz (int x, int fa) siz[x] = 1 ; maxx[x] = 0 ; for (int j = h[x]; j; j = nxt[j]) if (p[j] != fa && !vis[p[j]]) { calcsiz(p[j], x); maxx[x] = max (maxx[x], siz[p[j]]); siz[x] += siz[p[j]]; } maxx[x] = max (maxx[x], sum - siz[x]); if (maxx[x] < maxx[rt]) rt = x; } int dd[maxn], cnt;void calcdist (int x, int fa) dd[++cnt] = dist[x]; for (int j = h[x]; j; j = nxt[j]) if (p[j] != fa && !vis[p[j]]) dist[p[j]] = dist[x] + w[j], calcdist(p[j], x); } queue <int > tag;void dfz (int x, int fa) tf[0 ] = true ; tag.push(0 ); vis[x] = true ; for (int j = h[x]; j; j = nxt[j]) if (p[j] != fa && !vis[p[j]]) { dist[p[j]] = w[j]; calcdist(p[j], x); for (int k = 1 ; k <= cnt; k++) for (int i = 1 ; i <= m; i++) if (q[i] >= dd[k]) ret[i] |= tf[q[i] - dd[k]]; for (int k = 1 ; k <= cnt; k++) tag.push(dd[k]), tf[dd[k]] = true ; cnt = 0 ; } while (!tag.empty()) tf[tag.front()] = false , tag.pop(); for (int j = h[x]; j; j = nxt[j]) if (p[j] != fa && !vis[p[j]]) { sum = siz[p[j]]; rt = 0 ; maxx[rt] = inf; calcsiz(p[j], x); calcsiz(rt, -1 ); dfz(rt, x); } } int main () scanf ("%d%d" , &n, &m); for (int i = 1 ; i < n; i++) scanf ("%d%d%d" , &a, &b, &c), add_edge(a, b, c), add_edge(b, a, c); for (int i = 1 ; i <= m; i++) scanf ("%d" , q + i); rt = 0 ; maxx[rt] = inf; sum = n; calcsiz(1 , -1 ); calcsiz(rt, -1 ); dfz(rt, -1 ); for (int i = 1 ; i <= m; i++) if (ret[i]) printf ("AYE\n" ); else printf ("NAY\n" ); return 0 ; }
点分治的经典例题还有这个题目:luogu P4178 Tree
找重心 可以看到,找到正确的重心是保障算法复杂度的关键;首先下定义:一棵树的最大子树最小的点有一个名称,叫做重心;它有一个特点是以它为根的每一个子树的大小都不超过 n/2,这可以使用反证法来证明;正因为重心有这样的特点,所以每一次都选取重心进行递归,可以保障复杂度是 O(nlogn)。
找到子树也是依靠了这个特性:每次 DFS 整棵树,并且统计最大子树,就可以确定树的重心:
1 2 3 4 5 6 7 8 9 10 11 12 void findrt (int u,int fa) sz[u]=1 ,son[u]=0 ; for (int i=head[u];i;i=Next[i]){ int v=ver[i]; if (vis[v]||v==fa) continue ; findrt(v,u); sz[u]+=sz[v]; son[u]=max (son[u],sz[v]); } son[u]=max (son[u],size -sz[u]); if (son[u]<mx) mx=son[u],rt=u; }
这个过程的复杂度是 O(n) 的。
分治过程 不同的题目可能具体实现不同,但是大概结构如下:
1 2 3 4 5 6 7 8 9 10 11 12 void divide (int u) ans+=solve(u,0 ); vis[u]=1 ; for (int i=head[u];i;i=Next[i]){ int v=ver[i]; if (vis[v]) continue ; ans-=solve(v,edge[i]); mx=inf,rt=0 ,size =sz[v]; findrt(v,0 ); divide(rt); } }
有一个要提的地方是:在对于子树的 findrt 之前的传递全树大小的位置,直接传递了 sx[v];实际上这个地方应该传递的是 size=sz[v]>sz[u]?totsz-sz[u]:sz[v],但是这个错误的写法在这里并不会影响算法的正确性或者复杂度。数学证明可以看这里:传送门
动态点分治 上面的点分治只可以处理静态的问题,如果问题是动态的,也就是要求待修改状态的话,上面的方法就不能直接使用了;对于动态点分治问题来说,修改的只有点权值,整棵树的结构是不变的——这意味着我们每一次进行点分时选到的重心也是不变的;又因为遍历连通块是 O(n) 的,点分治的复杂度仅和上述的递归深度相关。
“树上的动态点分治相当于序列上的线段树”
点分树 简单的说,把上面说的点分治里每一层找到的重心之间连边,就构成了一颗高度为 logn 树,也就是点分树。
官方的说,就是通过更改原树形态使树的层数变为稳定 logn 的一种重构树;是点分治过程中选择的分治中心点构成的树形结构;常用于解决与树原形态无关的带修改问题,也就是上面说的那种动态问题。
得到点分树,就可以通过点分治每次找重心的方式来对原树进行重构:将每次找到的重心与上一层的重心缔结父子关系,这样就可以形成一棵 logn 层的树。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 #include <bits/stdc++.h> using namespace std ;typedef vector <int >::iterator IT;struct Edge { int to, nxt, val; Edge() {} Edge(int to, int nxt, int val) : to(to), nxt(nxt), val(val) {} } e[300010 ]; int head[150010 ], cnt;void addedge (int u, int v, int val) e[++cnt] = Edge(v, head[u], val); head[u] = cnt; } int siz[150010 ], son[150010 ];bool vis[150010 ];int tot, lasttot;int maxp, root;void getG (int now, int fa) siz[now] = 1 ; son[now] = 0 ; for (int i = head[now]; i; i = e[i].nxt) { int vs = e[i].to; if (vs == fa || vis[vs]) continue ; getG(vs, now); siz[now] += siz[vs]; son[now] = max (son[now], siz[vs]); } son[now] = max (son[now], tot - siz[now]); if (son[now] < maxp) { maxp = son[now]; root = now; } } struct Node { int fa; vector <int > anc; vector <int > child; } nd[150010 ]; int build (int now, int ntot) tot = ntot; maxp = 0x7f7f7f7f ; getG(now, 0 ); int g = root; vis[g] = 1 ; for (int i = head[g]; i; i = e[i].nxt) { int vs = e[i].to; if (vis[vs]) continue ; int tmp = build(vs, ntot - son[vs]); nd[tmp].fa = now; nd[now].child.push_back(tmp); } return g; } int virtroot;int main () int n; cin >> n; for (int i = 1 ; i < n; i++) { int u, v, val; cin >> u >> v >> val; addedge(u, v, val); addedge(v, u, val); } virtroot = build(1 , n); }
这里有一个技巧:每次用递归上一层的总大小 tot 减去上一层的点的重儿子大小,得到的就是这一层的总大小。这样求重心就只需一次 DFS 了;
实现修改 在查询和修改的时候,我们在点分树上暴力跳父亲修改;由于点分树的深度最多是 O(nlogn) 的,这样做复杂度能得到保证。
在动态点分治的过程中,需要一个结点到其点分树上的祖先的距离等其他信息,由于一个点最多有 logn 个祖先,我们可以在计算点分树时额外计算深度或使用 LCA,预处理出这些距离或实现实时查询;因为一个结点到其点分树上的祖先的距离不一定递增,所以不能累加;除此之外,一个结点在其点分树上的祖先结点的信息中可能会被重复计算:此时我们需要消去重复部分的影响。一般的方法是对于一个连通块用两种方式记录:一个是其到分治中心的距离信息,另一个是其到点分树上分治中心父亲的距离信息。
例题 ##### 「ZJOI2007」捉迷藏 给定一棵有 n 个结点的树,初始时所有结点都是黑色的。你需要实现以下两种操作:
反转一个结点的颜色(白变黑,黑变白); 询问树上两个最远的黑点的距离; 数据范围:n ≤ 1e5,m ≤ 5e5
求出点分树,对于每个结点 维护两个可删堆。 dist[x] 存储结点 x 代表的连通块中的所有黑点到 x 的距离信息, ch[x] 表示结点 x 在点分树上的所有儿子和它自己中的黑点到 x 的距离信息;由于本题贪心的求答案方法,且两个来自于同一子树的路径不能成为一条完成的路径,我们只在这个堆中插入其自己的值和其每个子树中的最大值;我们发现, ch[x] 中最大的两个值(如果没有两个就是所有值)的和就是分治时分支中心为 x 时经过结点 x 的最长黑端点路径。我们可以用可删堆 ans 存储所有结点的答案,这个堆中的最大值就是我们所求的答案。
我们可以根据上面的定义维护 dist[], ch[], ans 这三个可删堆:当 dist[x] 中的值发生变化时,我们也可以在 O(logn) 的时间复杂度内维护 ch[x] 和 ans。
现在我们来看一下,当我们反转一个点的颜色时, dist[x] 值会发生怎样的改变:当结点原来是黑色时,我们要进行的是删除操作;当结点原来是白色时,我们要进行的是插入操作;假如我们要反转结点 x 的颜色。对于其所有祖先 u,我们在 dist[u] 中插入或删除 dist(x, u),并同时维护 ch[x] 和 ans 的值;特别的,我们要在 ch[x] 中插入或删除值 0。
分治树深度 logn,堆操作时间复杂度是l O(logn),总时间复杂度是 O(nlog²n);
例题的代码(来自 OI Wiki):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 #include <algorithm> #include <cstdio> #include <cstring> #include <queue> using namespace std ;const int maxn = 100010 ;const int inf = 2e9 ;int n, a, b, m, x, col[maxn];char op;int cur, h[maxn * 2 ], nxt[maxn * 2 ], p[maxn * 2 ];void add_edge (int x, int y) cur++; nxt[cur] = h[x]; h[x] = cur; p[cur] = y; } bool vis[maxn];int rt, sum, siz[maxn], maxx[maxn], fa[maxn], dep[maxn];void calcsiz (int x, int f) siz[x] = 1 ; maxx[x] = 0 ; for (int j = h[x]; j; j = nxt[j]) if (p[j] != f && !vis[p[j]]) { calcsiz(p[j], x); siz[x] += siz[p[j]]; maxx[x] = max (maxx[x], siz[p[j]]); } maxx[x] = max (maxx[x], sum - siz[x]); if (maxx[x] < maxx[rt]) rt = x; } struct heap { priority_queue <int > A, B; void insert (int x) void erase (int x) int top () while (!B.empty() && A.top() == B.top()) A.pop(), B.pop(); return A.top(); } void pop () while (!B.empty() && A.top() == B.top()) A.pop(), B.pop(); A.pop(); } int top2 () int t = top(), ret; pop(); ret = top(); A.push(t); return ret; } int size () return A.size () - B.size (); } } dist[maxn], ch[maxn], ans; void dfs (int x, int f, int d, heap& y) y.insert(d); for (int j = h[x]; j; j = nxt[j]) if (p[j] != f && !vis[p[j]]) dfs(p[j], x, d + 1 , y); } void pre (int x) vis[x] = true ; for (int j = h[x]; j; j = nxt[j]) if (!vis[p[j]]) { rt = 0 ; maxx[rt] = inf; sum = siz[p[j]]; calcsiz(p[j], -1 ); calcsiz(rt, -1 ); fa[rt] = x; dfs(p[j], -1 , 1 , dist[rt]); ch[x].insert(dist[rt].top()); dep[rt] = dep[x] + 1 ; pre(rt); } ch[x].insert(0 ); if (ch[x].size () >= 2 ) ans.insert(ch[x].top() + ch[x].top2()); else if (ch[x].size ()) ans.insert(ch[x].top()); } struct LCA { int dep[maxn], lg[maxn], fa[maxn][20 ]; void dfs (int x, int f) for (int j = h[x]; j; j = nxt[j]) if (p[j] != f) dep[p[j]] = dep[x] + 1 , fa[p[j]][0 ] = x, dfs(p[j], x); } void init () dfs(1 , -1 ); for (int i = 2 ; i <= n; i++) lg[i] = lg[i / 2 ] + 1 ; for (int j = 1 ; j <= lg[n]; j++) for (int i = 1 ; i <= n; i++) fa[i][j] = fa[fa[i][j - 1 ]][j - 1 ]; } int query (int x, int y) if (dep[x] > dep[y]) swap(x, y); int k = dep[y] - dep[x]; for (int i = 0 ; k; k = k / 2 , i++) if (k & 1 ) y = fa[y][i]; if (x == y) return x; k = dep[x]; for (int i = lg[k]; i >= 0 ; i--) if (fa[x][i] != fa[y][i]) x = fa[x][i], y = fa[y][i]; return fa[x][0 ]; } int dist (int x, int y) return dep[x] + dep[y] - 2 * dep[query(x, y)]; } } lca; int d[maxn][20 ];int main () scanf ("%d" , &n); for (int i = 1 ; i < n; i++) scanf ("%d%d" , &a, &b), add_edge(a, b), add_edge(b, a); lca.init(); rt = 0 ; maxx[rt] = inf; sum = n; calcsiz(1 , -1 ); calcsiz(rt, -1 ); pre(rt); for (int i = 1 ; i <= n; i++) for (int j = i; j; j = fa[j]) d[i][dep[i] - dep[j]] = lca.dist(i, j); scanf ("%d" , &m); while (m--) { scanf (" %c" , &op); if (op == 'G' ) { if (ans.size ()) printf ("%d\n" , ans.top()); else printf ("-1\n" ); } else { scanf ("%d" , &x); if (!col[x]) { if (ch[x].size () >= 2 ) ans.erase(ch[x].top() + ch[x].top2()); ch[x].erase(0 ); if (ch[x].size () >= 2 ) ans.insert(ch[x].top() + ch[x].top2()); for (int i = x; fa[i]; i = fa[i]) { if (ch[fa[i]].size () >= 2 ) ans.erase(ch[fa[i]].top() + ch[fa[i]].top2()); ch[fa[i]].erase(dist[i].top()); dist[i].erase(d[x][dep[x] - dep[fa[i]]]); if (dist[i].size ()) ch[fa[i]].insert(dist[i].top()); if (ch[fa[i]].size () >= 2 ) ans.insert(ch[fa[i]].top() + ch[fa[i]].top2()); } } else { if (ch[x].size () >= 2 ) ans.erase(ch[x].top() + ch[x].top2()); ch[x].insert(0 ); if (ch[x].size () >= 2 ) ans.insert(ch[x].top() + ch[x].top2()); for (int i = x; fa[i]; i = fa[i]) { if (ch[fa[i]].size () >= 2 ) ans.erase(ch[fa[i]].top() + ch[fa[i]].top2()); if (dist[i].size ()) ch[fa[i]].erase(dist[i].top()); dist[i].insert(d[x][dep[x] - dep[fa[i]]]); ch[fa[i]].insert(dist[i].top()); if (ch[fa[i]].size () >= 2 ) ans.insert(ch[fa[i]].top() + ch[fa[i]].top2()); } } col[x] ^= 1 ; } } return 0 ; }
还有一个经典的例题:洛谷 P6329 【模板】点分树 | 震波
边分治 边分治和点分治一样属于树分治的一部分,和点分治也有足够的相似之处:选取一条边,将树尽量均匀地分为两个部分;但是相比于点分治,边分治对于与度数相关的问题有着很大的优势,同时边分治也是解决树上最优化问题的一种重要的算法。
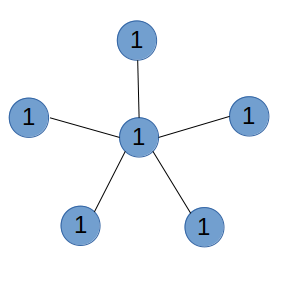
但是这样存在一个问题:当一棵树是有多个大小相近的子树的时候比如菊花图,复杂度就会变差:
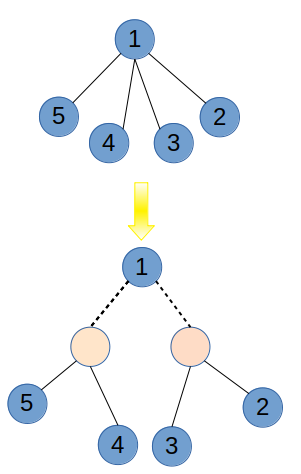
tree-divide1.png ↑ 菊花图 ↑ 在这种情况下,无论怎么划分复杂度都会变成 O(n²);考虑到如果根节点的孩子减少的话,就可以缓解这种压力,最优的树型就是二叉树;所以可以重构这颗树,利用插入虚点的方法将一颗多叉树转化为二叉树从而保证分治的复杂度 O(nlogn) ;但是因为插入了 O(n) 个虚点,最多会引入两倍的常数。
这种重构树的建树方法和线段树的建树很像;新插入的虚点维护的数据可以根据题目要求来确定——比如当统计路径长度时,将原边边权赋为 1, 将新建的边边权赋为 0 即可;几乎所有的点分治的题边分都能做,但是常数上有差距。
至于分治的过程,和点分治依然是相似的:每次分治时找到一条分治中心边,使这条边两端的两个联通块中较大的一个尽量小;在以分治中心边为界限分开而得到的两个连通块中,统计路径经过分治中心边的答案;然后将分治中心边断开,递归分治中心边两端的两个联通块。
找中心边 和点分治非常相似:通过统计一条边的两侧的子树的大小,找到较大的一侧子树大小最小的边;在递归的时候应当将当前的中心边打上删除标记,以避免统计错误。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 inline void findct (int u, int fa) siz[u] = 1 ; for (int i = head[u]; ~i; i = gra[i].nxt) { int v = gra[i].to; if (del[i >> 1 ] || v == fa) continue ; findct(v, u); siz[u] += siz[v]; int vsiz = std ::max (siz[v], sum - siz[v]); if (vsiz < ctsiz) { ct = i; ctsiz = vsiz; } } }
代码中的 sum 是调用该函数时设置的当前连通块的大小。
树重构 重构树的递归过程是:先重构子树,再将重构完成的子树们二分连接到虚点上,效果大概如下图所示:
tree-divide2.png 下面是一种参考的树重构的实现方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 inline void rebuild (int u, int fa) int ff = 0 ; for (int i = heado[u]; ~i; i = grao[i].nxt) { int v = grao[i].to, w = grao[i].w; if (v == fa) continue ; if (!ff) { addedge(u, v, w); addedge(v, u, w); ff = u; } else { int k = ++n; addedge(ff, k, 0 ); addedge(k, ff, 0 ); addedge(k, v, w); addedge(v, k, w); ff = k; } rebuild(v, u); } }
但是上面的实现并不是边分治中重构树的唯一选择;大可采用其他的实现来完成这项工作。
例题 ##### SP2666 QTREE4 - Query on a tree IV 给定一棵 n 个点的带边权的树,点从 1 到 n 编号;每个点可能有两种颜色:黑或白;一开始所有的点都是白色的;定义 dist(a, b) 为 a-b 路径上的权值之和;可以进行操作:
C a:反转 a 点的颜色;A:查询 dist(a, b) 的最大值,a b 都是白色,且可相同;查询时若树上无白色点,输出 They have disappeared.;N, Q ≤ 1e5,边权c ∈ [-1e3, 1e3]。
当然,这个题目也可以使用点分治来做;但是这里使用边分治的方法来解决:在中心边位置维护两个堆,分别表示左右子树的各个白点距离;单独维护每个分治结构的答案,就可以在一个统计最大值的时候顺带把子分治结构的最大值也计算进来,这样询问的时候只需要询问根分支结构的答案即可;
在加点的的过程中,记录下这个点会影响到的堆的数据:变白要把这个点放进堆里,变黑只需要打标记;在每一次更新答案的时候,从堆顶把黑点全部删除;如果用数组或者 vector 来存的话,这个更新要根据倒序,因为倒序才是分治结构从底向根的顺序。
参考代码(Code by KSkun, 2018/3):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 #include <cstdio> #include <cstring> #include <vector> #include <algorithm> #include <queue> typedef long long LL;inline char fgc () static char buf[100000 ], *p1 = buf, *p2 = buf; return p1 == p2 && (p2 = (p1 = buf) + fread(buf, 1 , 100000 , stdin ), p1 == p2) ? EOF : *p1++; } inline LL readint () register LL res = 0 , neg = 1 ; register char c = fgc(); while (c < '0' || c > '9' ) { if (c == '-' ) neg = -1 ; c = fgc(); } while (c >= '0' && c <= '9' ) { res = res * 10 + c - '0' ; c = fgc(); } return res * neg; } inline bool isop (char c) return c == 'A' || c == 'C' ; } inline char readop () char c; while (!isop(c = fgc())); return c; } const int MAXN = 200005 , INF = 2e9 ;int n, q, col[MAXN], ans;struct Edge { int to, w, nxt; } gra[MAXN << 1 ], grao[MAXN << 1 ]; int head[MAXN], heado[MAXN], ecnt, ecnto;inline void addedge (int u, int v, int w) gra[ecnt] = Edge {v, w, head[u]}; head[u] = ecnt++; } inline void addedgeo (int u, int v, int w) grao[ecnto] = Edge {v, w, heado[u]}; heado[u] = ecnto++; } inline void rebuild (int u, int fa) int ff = 0 ; for (int i = heado[u]; ~i; i = grao[i].nxt) { int v = grao[i].to, w = grao[i].w; if (v == fa) continue ; if (!ff) { addedge(u, v, w); addedge(v, u, w); ff = u; } else { int k = ++n; col[k] = 1 ; addedge(ff, k, 0 ); addedge(k, ff, 0 ); addedge(k, v, w); addedge(v, k, w); ff = k; } rebuild(v, u); } } bool del[MAXN << 1 ];int ct, ctsiz, sum;int siz[MAXN], msz[MAXN];inline void calsiz (int u, int fa) siz[u] = 1 ; for (int i = head[u]; ~i; i = gra[i].nxt) { int v = gra[i].to; if (del[i >> 1 ] || v == fa) continue ; calsiz(v, u); siz[u] += siz[v]; } } inline void findct (int u, int fa) for (int i = head[u]; ~i; i = gra[i].nxt) { int v = gra[i].to; if (del[i >> 1 ] || v == fa) continue ; findct(v, u); int vsiz = std ::max (siz[v], sum - siz[v]); if (vsiz < ctsiz) { ct = i; ctsiz = vsiz; } } } struct DisData { int u, d; inline bool operator <(const DisData &rhs) const { return d < rhs.d; } }; std ::priority_queue <DisData> s[MAXN][2 ];int cnt;struct NodeData { int bel, side, dis; }; std ::vector <NodeData> ndata[MAXN];inline void caldis (int u, int fa, int d, int t, int l) if (!col[u]) { s[t][l].push(DisData {u, d}); ndata[u].push_back(NodeData {t, l, d}); } for (int i = head[u]; ~i; i = gra[i].nxt) { int v = gra[i].to, w = gra[i].w; if (del[i >> 1 ] || v == fa) continue ; caldis(v, u, d + w, t, l); } } int mx[MAXN], lch[MAXN], rch[MAXN], ctw[MAXN];inline void update (int p) while (!s[p][0 ].empty() && col[s[p][0 ].top().u]) s[p][0 ].pop(); while (!s[p][1 ].empty() && col[s[p][1 ].top().u]) s[p][1 ].pop(); if (s[p][0 ].empty() || s[p][1 ].empty()) mx[p] = 0 ; else mx[p] = s[p][0 ].top().d + ctw[p] + s[p][1 ].top().d; if (lch[p]) mx[p] = std ::max (mx[p], mx[lch[p]]); if (rch[p]) mx[p] = std ::max (mx[p], mx[rch[p]]); } inline int divide (int u) calsiz(u, 0 ); ct = -1 ; ctsiz = INF; sum = siz[u]; findct(u, 0 ); if (ct == -1 ) return 0 ; int x = gra[ct].to, y = gra[ct ^ 1 ].to; del[ct >> 1 ] = true ; int t = ++cnt; ctw[t] = gra[ct].w; caldis(x, 0 , 0 , t, 0 ); caldis(y, 0 , 0 , t, 1 ); lch[t] = divide(x); rch[t] = divide(y); update(t); return t; } inline void setwhite (int u) for (int i = ndata[u].size () - 1 ; i >= 0 ; i--) { NodeData d = ndata[u][i]; s[d.bel][d.side].push(DisData {u, d.dis}); update(d.bel); } } inline void setblack (int u) for (int i = ndata[u].size () - 1 ; i >= 0 ; i--) { NodeData d = ndata[u][i]; update(d.bel); } } int ut, vt, wt;char op;int main () memset (head, -1 , sizeof (head)); memset (heado, -1 , sizeof (heado)); n = readint(); int white = n; for (int i = 1 ; i < n; i++) { ut = readint(); vt = readint(); wt = readint(); addedgeo(ut, vt, wt); addedgeo(vt, ut, wt); } rebuild(1 , 0 ); divide(1 ); q = readint(); while (q--) { op = readop(); if (op == 'A' ) { if (!white) { puts ("They have disappeared." ); } else if (white == 1 ) { puts ("0" ); } else { printf ("%d\n" , mx[1 ]); } } else { ut = readint(); col[ut] ^= 1 ; if (col[ut]) { setblack(ut); white--; } else { setwhite(ut); white++; } } } return 0 ; }
不只是这个题目,很多的点分治的问题都可以使用边分治解决,这里就不贴其他题了。
推荐题目 除了文章中出现的讲解了的和没讲解的例题之外,还可以做一做下面这些题目:
推荐的题目参考了网络上的资料。
参考资料 因为这篇文章参考了大量其他巨佬神犇的博客和资料,所以基本上没有什么原创性可言;借物表如下:
都是因为 DDL,理解万岁,理解万岁(