




洛谷ACM春季多校训练营:第三场

因为是版权原因,这里并不能公开的放题目链接和题目的讲评之类的东西。各位看官就将就着看看我说吧==
又是一场接近爆零的比赛呢(笑
打的很丑,补题不及时罪加一等。题目不多,难度不做评价,但是就英语来说题目都很好懂,读起来都不费劲就是自己做不出来。……所以就不多废话,直接讲题目。
首先是出题人自己对于这次题目难度的评价:
| 简单题 | 中档题 | 较难题 |
|---|---|---|
| B,C,D | H,E,G | A,F |
然后,我根据出题人当晚讲评的顺序来说这些题目:
B - Bit fixer
给你一个二进制串,宇宙射线每天会取反一个bit,你很辣鸡,每天只能掰反一个bit;给你一个目标串,问你最少多少天能完成任务。数据规模在1e5之内。
引导
官方讲评在说这个题目之前说了一道下面这样的题目。
这题来源于一道CF题目:
有一条船,速度v1;水速每天都会变,船的方向也可以每天调整,但在一天中方向都不变;而且船每天的航行时间相同。给出两点距离,以及每天的水流大小和方向,问最少需要花多少天?
对于这个题:因为船和水的位移都是矢量,如果把船和水的位移加起来等于起点到终点的向量,就表示船可以到达终点。 又因为矢量相加符合交换律,所以可以先计算水的总位移,与起点->终点的向量相减,就可以得到船要走的位移。
因此,这个题目,只要枚举天数,得到船应走的唯一,判断能不能走完就行了。
所以这个题目,仔细想想也可以用这种思想来解决。
分析
二进制串,每次会被动的变一次;你每次可以修改一位。如果把二进制串也看成向量的话,那么在第x天,你最多只能满足目标串和当前串相差的模≤x的情况。因为每天原串都会变化,所以模也在不断变化;又因为相反一位的值,也就是异或,也是满足交换律的;所以也可以像上面那个题目那样。
为什么反复提到交换律呢?我们的做法,相当于把每个时间片的“外力”和“内力”造成的偏移分离之后统一考虑:然而题目原模型是交错的。只有满足了交换律,我们才能随意挪移一个式子中的不同项,整理组合从而简化。
实现的话,直接枚举然后求差的话,1e10就爆炸了。但是实际上,因为这是一个二进制串,每次只需要更新修改的那一位的状态就可以了(也就是出题人说的曼哈顿法),或者也可以二分答案。
二分单调性:显而易见的,因为外力和内力是可以抵消的。当某个x可以达成目标之后,之后只需不断抵消内外力即可。
总而言之,有了交换性,随便怎么整理(移项)都可以哦。
误区
因为题目只让我们求一个具体的值——也就是能不能在指定天数内达成目标,而不是求一个具体的方案。所以完全可以通过挪移整理来简化模型。最开始我的分析是顺推,分不同的情况,使用队列维护修改的优先级。这样做也许是对的,但是我赛场上没有分析出来(逃),这题就这么死了。事实上只要能想到是只求天数的话,完全没有必要这样麻烦自己。
此外,因为这个题目时求一个最小天数的,且显然具有二分单调性——如果能想到一个二分答案,即使是我那样处理来判别,也是有可能做出来的。总而言之,做不出来就是你傻了。
代码
这是使用优化的枚举的代码:
1 |
|
有一个需要注意的就是,输入中的这个index实际上是从右到左的,所以需要进行处理之后才可以使用。当然也可以输入的时候就从后向前存储。
C - Coprime
给你一个整数序列,再给你一个操作:每次你可以把某个数变成任意的另一个数;问最少经过多少次操作,使得序列中任意相邻两个数互质。数据规模1e5。
分析
首先,互质也就是说 gcd(a, b) =1. 如果a b中有一个数是1,那这就是板上钉钉的了;所以要改,肯定就是改成1.
然后对于具体的数列来说,可以使用贪心处理:假设从左向右处理,如果a b相邻但是不互质,最好肯定还是修改b:因为改a只能保证和b互质,而改b还可以保证和未来的c也一定互质。
代码
1 |
|
豆知识(模外挂):其实比起a%b取模,加上判断地使用a-s/b*b来的更快哦。
D - Dodo bird painting
有一根绳子,每次往绳子上滴一滴墨水,墨水会一固定速度扩散;给出滴墨水的时间和位置,问最早什么时候, 绳子完全被墨水覆盖。绳子长度是1e9,墨水数量1e5.
分析
这其实是一个二分套路题。
虽然不是大家都喜欢的经典最大求最小或者最小求最大的问题,但是依然是可以用二分求解:
- 二分单调性:如果某个时间t恰好可以给整条绳子染色,那么小于t的时间一定不能全部染色,且大于t的时间一定也可以给整条绳子染色。
- 问题特性:直接求解(比如DP?),至少需要O(n²)的时间;而确认一个答案可不可以全部染色,只需要O(n)的时间。符合二分答案问题的特点
综上所述,采用二分答案的方法,把最优化问题转化为可行性问题。 这个题目就可以做了,复杂度大约是O(nlogk),k和墨水的传输速度和绳子长度相关。
具体的说,对于具体的时间,求解这个时间下每滴墨水可以染色的区间,再按顺序合并:如果出现无法合并的情况,就说明不可全部染色。
误区
其实不想话太多笔墨来说自己是怎么错的。但是既然蠢了,就要挂起来婊着。我最开始想着是DP每两滴墨水之间的绳子长度被墨水染色需要的时间,再考虑墨水“跨界点染色”的事情,也就是说DP。这确实是模拟的思路,但是会TLE。并且只要是这种DP,就必须要确认每滴墨水的可能性。可以说就是没什么太大的优化空间,复杂度O(n²),对于这个题目的1e5的数据规模,那是死的透透的。
其次是实现方面的一些事情:合并区间并不可以贪心!除非经过稳健的排序。否则,位置处在后方的区间仍然可以覆盖前面并未合并的区间,如果贪心退出就判断错误了。
代码
理清思路的情况下还能吃一发WA也是没谁了。只能说不愧是我==
写代码的时候还是不能太过于自以为是了。这里的check要做的事是合并区间,而这个行为并不能通过贪心来节约时间——原因上面也提到了。
1 |
|
有几个比较坑的地方:首先输入的墨水的位置和速度都是浮点数——这我还是查了标程才知道的;然后,关于check函数里面的rr.right的问题:看起来这里的max判断是非必要的,因为我已经排序了;但是因为eps的存在以及一些其他的原因,这里必须要强制保证才可以AC。
另一件事情:如果你不想要使用std::pair<T1,T2>的默认大小判断的话,就干脆的建立一个新类,而不是重命名一个pair——即使你显式的重写了operator<,它用的是什么也不为人知——其实这可实验验证。
H - Huaji robot
有一个n*n的网格图,坐标范围为[(1,1),(n,n)];横纵坐标互质的地方不能通行;每次移动都是八个方向的移动;给定起点和终点,问能否到达。地图大小n的数据规模是1e9.
引导
出题人讲评的幻灯片上,有下面这段文字:
◦ 推公式?我菜得一比,不会推公式!
◦ 此题更可行的办法是打表+猜结论。
◦ 打表小技巧:当打出的表只有0和1时,就不需要用空格隔开,进一步地,把1换成空格,这样每一个数字和它周围的 关系就更清楚。
这个题目的障碍物非常的奇特——横坐标和纵坐标互质则不能通行。看起来没什么规律,可以打个表来看看特点。这里就直接写打表可以得到的信息:
- x=y对角线除了x=1时均可以通行:正确性显然
- 对于质数行列,会有长段连续的不可通行区域
- 连通块被质数的行列等切成了比较规则的区域
综上所述,可以猜想:除了与整张图的主对角线相连的,所有的连通块都不会太大。因为会被编号时质数行列的直线切开。虽然质数直线并不是连续的,但是还是可以证明每个连通块不大:
因为每个数的质因子数是 log 级别的,所以在 x=p1 和 x=p2 之间,至多会有 log n×(p2-p1) 个点,把相邻的联通块连接起来。所以每个块的大小是 log n×max(pi-pj) 级别,其中 pi 和 pj 是相邻的两个质数。
又因为,1e9的范围内两个质数的差不会太大——实际上1e9内,最大的质数间距为282。这真的不大,这样就可以有一种思路:
从起点和终点开始搜索,只要到达 y=x≠1 的点即视为联通
使用 map、哈希、偏移量数组来做这次搜索
这样这个题目就可以做了,
分析
其实也并不需要打表,稍微想想也可以得到上面看出来的两点结论:对角线联通,质数直线阻塞。然而这种题目似乎除了搜索别无他法,只要能够简化搜索就可以做了。也可以得出双向搜索,使用 map 存储遍历情况来做。
但是在实现的过程中还要注意,可能两个点都连接到
当然,这种奇怪的题目也有可能是一个结论,这个时候就别无他法只能当场去世了。
代码
使用 map 作为访问数组的代码:
1 |
|
第一次写的时候不知道犯了什么浑,结果按照标程的方法布局代码就过了,不是很懂…… 也许两头搜索就应该使用 vis 数组记录具体哪一次搜索到达的信息吧。
E - Eluos blocks
给了一个由三种俄罗斯方块拼成的图形,记为ABC;A类俄罗斯方块只有一个,而其他的有无数个;求出这唯一的A类方块的位置。整个图形的规模小于500。求出解的数量。并且按照指定的顺序输出所有的解。
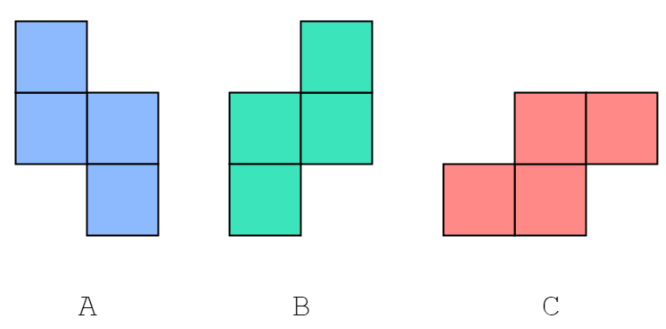
引导
这种一看就是考智商的思维题。这道题再加大难度之前是这样的:
弱化版的条件有这样的区别:无B类方块,依然是一个A类和若干C类方块
这种情况下,只有两种不同的图形,图形之间的差距挺容易被对比出来的,这里直接说:
- 显然,A是斜杠的对角线的两个方块缺失,C是反斜杠的对角线。
- 即使这些方块不断的堆积,这种特性也会得以保留。
- A图形跨三行:首尾两行只有一个方块,中间一行有两个;C跨两行,每行两个。
那么这题的解法就有眉目了:可以利用最后一条特性,确定A所在的水平位置,再搜索垂直方向,找到满足条件的情况输出即可;也可以利用前两条特性,找到最左上角的“孤立”方块,若右侧无方块那就可以肯定是A,否则是C,删去。这种做法的正确性也可以比较容易的讨论证明。
现在的情况是不仅有AC,还有B类方块;这样的话上面的方法就不行了,我们需要去找新的规律:
分析
虽然对角线上的两个方块的独特性已经消失了,但是参考上面的特性,我们还是可以找出新的特性:从反对角线方向观察方块的“厚度”,也可以观察到这样的特点:
- A类方块占有斜杠方向对角线的四列,每列有一个方块;
- B类、C类方块占有斜对角线方向的两列,每列有两个方块;
这样就和上面简单版题目的第三条特性相似,可以使用同样的方法来做了:通过统计对角线的方块数量,找到数量是奇数的四列方块,然后再遍历某对角线上的所有方块,检查它们是A的一部分时的正确性,就可以在O(n³)的时间内求解。所有的解都会出现在这个范围内。
这里说的斜杠方向指的是将整个图逆时针旋转45°。旋转之后可以得到图形的“列”和“厚度”。
这个题目似乎实际上O(n⁴)的算法也可以卡过去。也就是说枚举能过的。
代码
特别注意:输出的坐标是需要排序的。也就是说这题没有SPJ。
1 |
G - Game
给5个整数,要求使用加减乘除括弧运算符以及前4个数字拼成一个算式,使得算式结构等于第5个数;问是否可以构造出这样的算式。
分析
非常经典的问题:你可以不停枚举,枚举数字排列,枚举运算符,枚举括号位置,然后求解验证;也可以每次选出两个数字和一种运算符计算,将计算结果丢回去,重新选择计算直到只剩下一个数字,都可以。怎么做都可以做出来,暴力只要写对了也可以AC。
误区
这个游戏和常规24点游戏有一个根本上的不同:数字的顺序是可以随机调换的,最后构造的算式中,数字出现在式子中的顺序未必是输入的顺序。如果按照一般24点写死的话就会死。这有可能就是赛场上我和队友没有AC这个题目的原因所在。
代码
首先四选二,再三选二,枚举所有可能的运算方式(包括反向的减法除法):
1 |
|
现在觉得适当的多用用lambda表达式声明一些函数还是蛮好的== 有点香
A - Able was I ere I saw Elba
给一个长度为 n 字符串,以及m个操作;每个操作能让你花 c 个代价把字符 a 变成字符 b;对于串中的所有子串[l,r],都可以花一个最小的代价来把它变成回文串;问对于所有n*(n-1)/2个子串,最小代价和是多少。
引导
首先题目里是子串,而不是子序列(否则个数也不对了),子串是连续的。
和很多的区间数据结构题目不同,这个题目并不是每次询问一个空间内的子串,而是所有可能的子串。这和随机询问不同,是一种特殊性,可以加以利用;下面我们考虑一对字符 s[i] 和 s[j] 的贡献:
- 设 i j 的对称轴为 k,显然k是中点;显然,所有以k为对称轴的子串都会受到同样来自 i j 的贡献;
- 这样的子串数量是 min(i,n-j+1),这也是显然的。
- 直接枚举复杂度太大,但是可以简化:若贡献 i 次,那么一定满足 i < n-j+1, j 的取值有范围;
- 假设 j 的最大值为 m,则 i < n-m+1 => m<n-i+1 。
至于让 i j 字符相同,可以修改两者中的一个,也可以同时修改两个字符使他们的值相等,找到最小的花费。又因为它们有不同的贡献度,还要记得加算倍数。事实上,分贡献的倍数讨论就可以了。
根据上面的分析,可以确定这样的实现思路:
- 根据奉献的次数来分别处理:奉献次数为 i 时,也就是a[i]与所有的 a[t] (i<t<n-i+1) 不发生冲突的最少花费的和;奉献 j 次时,就是反向同理;
- 因为字符集只有26,可以处理每个字母数量的前缀和,从而快速得出区间 (i,n-i+1) 内存在的不同字符个数,以累加对答案的总贡献;
- 因为变化字符使得相等有多种方案,需要预先处理任意两个字符的转化代价,再处理消除任意两个冲突字符的代价;这可以使用 Floyd 预处理。
这样,就可以着手实现这个题目了。
分析
首先看懂题目。我们选择样本不大且有代表性的样例2:
| 输入数据 | 输出数据 |
|---|---|
| 5 2 aabaa a b 1 b a 10 | 6 |
字符串"aabaa"一共有十个子串,下面只列出需要修改字符的子串:
- "aaba", "abaa" => "abba":a -> b,消费1*2
- "aab", "baa" => "bab":a -> b,消费1*2
- "ab", "ba" => "bb":a -> b,消费1*2
综上所述,将这个字符串的全部子串变为回文串的总消费是6,也就是要求解输出的值。
首先维护一个字符集的前缀和;然后根据输入的转化成本信息,使用Floyd求出所有可互相转化的字符转化的最低成本;然后考虑解决冲突:当字符 i j 不同时,将它们改成相同的时候所需要的最低成本;随后遍历串中每一个字符,只考虑单个字符的贡献以统计答案。具体地说,统计答案是这样做的:
- 对于下标为 [0,n-1] 的字符串的第 i 个字符:它的左侧有 i 个字符,右侧有 n-i-1 个字符;
- 若字符靠左侧,则 i 较小;这里仅考虑 i 作为对称轴左侧字符的情况,因为右侧的情况会被更小的 i 考虑到;
- 若字符 i 在左侧,那么它的左侧还可能有 [0,i] 个字符;这里仅考虑 i 的情况,因为其他情况会被从右侧对称考虑到;但是仍然要计算所有的可能前缀的回文串;
- 问题转化成:当子串的对称轴左侧最前端有 substr(0,i) 的前缀时,字符 i 可以为回文串奉献的最小修改成本;
- 因为有了长度为 i 的前缀,所以可能在子串中和 i 对称的字符只有下标为 [i+1,n-i-1] 的字符;尝试修改字符 i 使得字符 i 与每个这些字符都相等;
- 因为有可选的长度为 i 的前缀,所以上述计算得到的奉献还需要加算奉献倍数 i+1;
- 当字符 i 在右侧时,需要注意的是:使用全部后缀的情况已经被对应的左侧字符考虑过了,所以考虑的对称字符只有下标为 [n-i, i-1] 的字符。
- 特别注意,字符串长度为奇数的时候,最中间的一个字符单独计算贡献时不能带来任何贡献;
注意上述的所有细节,方可写出这个题目的代码。
代码
1 |
F - Fake information
空间中有 m 个点,有 n 个粒子在这些点上随机运动;开始时所有粒子处在1号点;每轮运动,粒子都会随机运动到其它另一个点,运动持续无数次;设 d[i,j] 表示第 i 个粒子和第 j 个粒子运动轨迹的最长公共前缀,求 max{d[i,j]} 的期望值。数据规模是100.
引导
分析
后记
菜呢,是真的菜。签到题的思路全部歪了,到最后除了最简单的划水题,一个题目也没有做出来。甚至根本都没有向二分答案的方向上去想。